こんにちは。ワントゥーテンでAIエージェントの開発に参加していることが多い、エンジニアの服部(@hatt_takumi)です。
2023年04月29日、30日に開催された、Maker Faire Kyoto 2023にて、ChatGPTを使った対話型ロボットを展示したので、その機能の一部について紹介したいと思います!

事前に見えていた課題
まず事前に、これまでの製作経験から、以下のような課題が見えていました。
- そもそもそんなに話しかけてもらえないかもしれない
- ChatGPTに繋いで会話できるロボットっていっぱい出てくるんじゃ…
私は普段から、チャット型のAIエージェントの製作に関わっていることが多いのですが、結構な頻度で出てくるのが、せっかく作ったエージェントにまったく話しかけてもらえない問題です。そもそも、案件として製作する場合は、そこまで設計にリソースを割くことができず、”会話を開始してからの受け答え”の部分しか作らないケースが多いです。
この場合、何もしていないときのエージェントは、ただただじーっと佇んでいるだけの状態となり、声かけを行うことに対して非常に心理的障壁の高い状態となります。
また、2023年04月のこのころはChatGPT全盛期。ちょうどGPT-4等もリリースされ、テキスト生成系のAI界隈は沸きに沸いておりました。SNSなどを眺めていても、TLがChatGPTを使った大喜利状態になっているくらい、日々メーカーたちが短期間で開発を回していました。おそらく、ChatGPTを使った会話コンテンツなど、会場に20個ぐらい出てくるでしょう…
対策
と、いうわけで、ただChatGPTと音声認識、音声合成を繋いだだけのコンテンツでは、目新しさもなく、かつ誰にも話しかけてもらえないロボットが完成してしまうことは目に見えていました。なので、会話していない時でも、なんとなく見ていて楽しいロボットにしよう!というのをコンセプトに製作してみました。
色々な機能を実装したのですが、今回はそのうち、①ステートの定義と、②音認識の利用の二点に関して紹介します!
ステートの定義
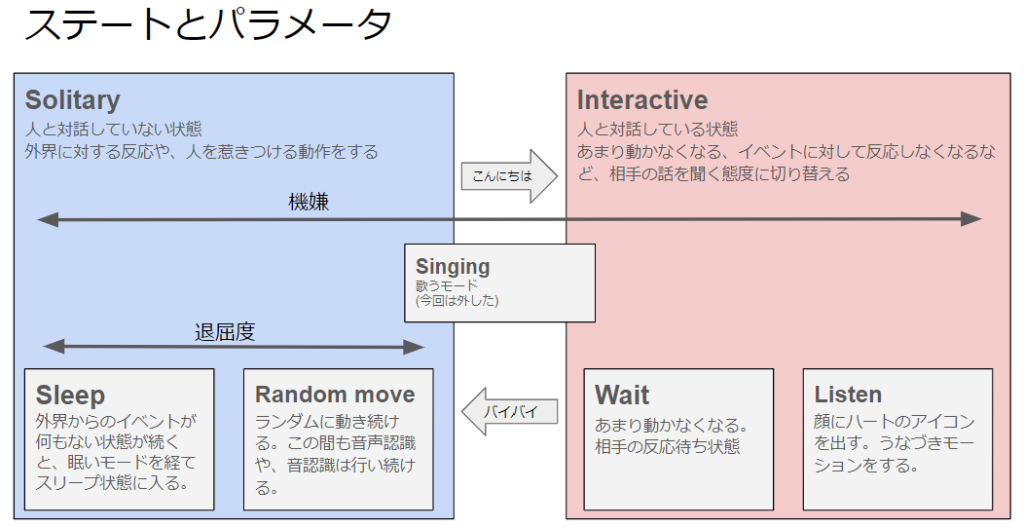
まず、ロボットのステートを、対話している状態、していない状態で、Interactive, Solitaryの二つに分けます。
この二つの状態のうち、会話していない状態であるSolitaryの時に、人目を引くような振る舞いを入れることで、利用者を対話へと促そうとしました。
ロボットは「こんにちは」の認識をきっかけにInteractiveに、「バイバイ」の認識をきっかけにSolitaryへとステートを切り替えます。
音認識の利用
外界への反応を作るために、音声認識ではなく音認識を利用してみました。
マイクから入ってくる音に対してリアクション出来るように、TensorflowのAudio classificationを利用して、Sound Event Detectionを行いました。
https://www.tensorflow.org/lite/examples/audio_classification/overview?hl=ja
音認識を使えば、音声認識では難しい、体験者の”笑い”や、”うーん、、”といった唸り声なども認識することができ、より体験者の感情に応じたリアクションが出来るはずです。
実際の実装
Audio classificationのモデルのリストから、いくつか発生しそうなものをピックアップしてリアクションを登録しました。
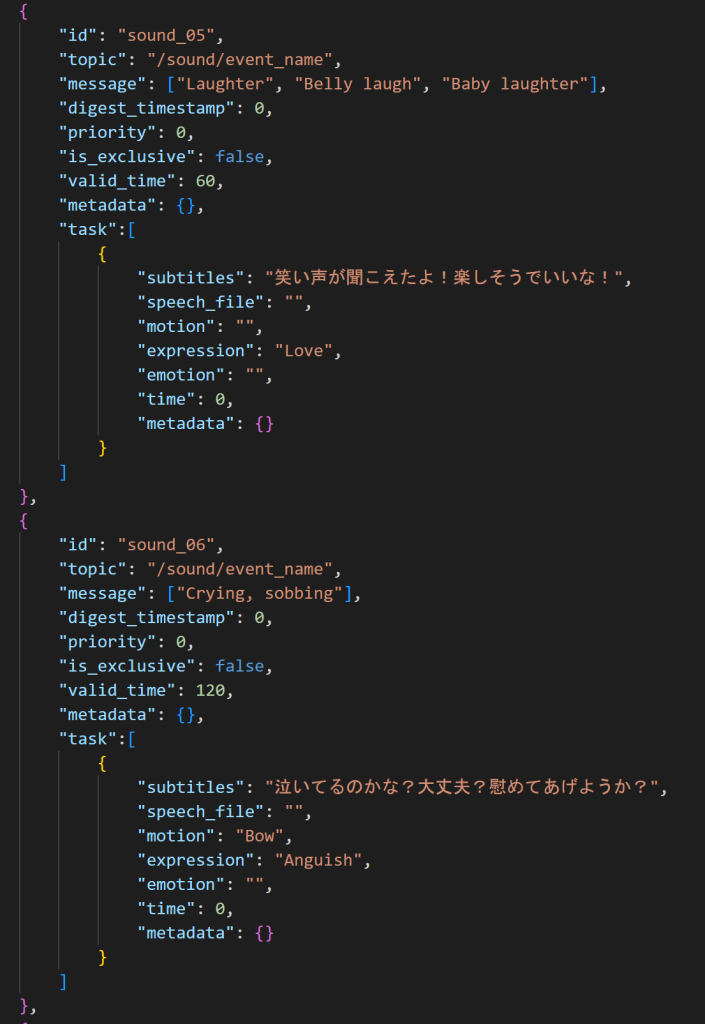
発生頻度や、個別の閾値なども同時に管理しています。
結果
なぜかめっちゃ話しかけられる…
結論からいうと、効果はあったのかなかったのかよくわからないという結果になってしまいました。
話しかけやすいように、存在に気づいてもらえるようにと、会話していない時間を様々な手法でデザインしたのですが、なんと当日はほとんど空き時間なく誰かに話しかけていただいており、会話していない、Solitaryのステートにいる時間がほとんどありませんでした…
おそらく、当日がメーカーフェアの会場という、特殊な場だったことが原因かと思われます。モノづくり大好きな人たちが集まる場なので、普段より興味をもってくれる方が多かったように思います。
また、隣のブースでやっておられたVRコンテンツが非常に人気で、並んでいる列の横でロボットが動いている状態だったので、順番待ちの間に遊んでくれる方もたくさんいました。
しかし、私も長い時間ロボットのそばにいたのですが、二日間で数度、実装したSolitaryイベントが発火しており、その際には体験者にはとても喜んでもらえました。
体験者には子供がとても多かったのですが、ロボットの反応に、何も言わずニコッとしてくれるのがとても嬉しかったです。
まとめ
サンプルとしては少なかったですが、ロボットへの話しかけに対する心理的障壁をなくすために、これらの実装は有効に働きそう(に思います)。
また、今回のような、ずっと話しかけられ続けるような体験だと、上手く返答をしてあげないと、体験者はすぐに何を聞いていいかわからなくなるようでした。
- 今日の天気は?
- 1+1は?
- 好きな食べ物は?
の三つの質問がすごく多かったです。
今後は、カメラなどの他のセンシング項目を追加したり、ステートをもっとシームレスに変化させて、会話中に様々なセンシング情報を基にした内容を盛り込むようにしたいです。そうすれば、もっと話題の広がりのある発話をしていけるようになると思います!
最後に、MakerFaireKyoto 2023 とても楽しかったです!