

はじめに
こんにちは、CGデザイナーの高睿(こう えい)です。
AI技術の進化とともに、3Dモデル生成AIは、テキストや画像から直接3Dデータを作成する手法として注目されています。
従来は専門的なスキルや高価なツールが必要だった3Dモデリングが、初心者でも短時間で高品質なモデルを作成できるようになりました。 さらに、AIを活用することで、作業効率の向上、コスト削減、初心者でも利用可能なユーザーフレンドリーなインターフェースなどの利点が得られます。 今後、AI技術の進化により、3Dモデリング分野でも新たな可能性が広がることが期待されます。
3Dモデル生成AIサービスの紹介
近年、3Dモデル生成AIサービスが多数登場していますが、それぞれの生成品質、速度、料金体系は多岐にわたります。
多くのサービスを試した結果、今回は特に操作が簡単で高品質な4つの3Dモデル生成AIに焦点を当てて紹介します。これにより、AI探す時間を節約し、迷うこともなく、皆さんの作業効率向上に役立てていただければと思います。
- 無料AIサービス

Tripo V2.5
主観的ですが、
現時点で最も優れた、生成効果と高い精度を誇る3Dモデル生成AIです。
主な機能
テキストからの3Dモデル生成:ユーザーが入力したテキストプロンプトに基づき、AIが対応する3Dモデルを生成します。
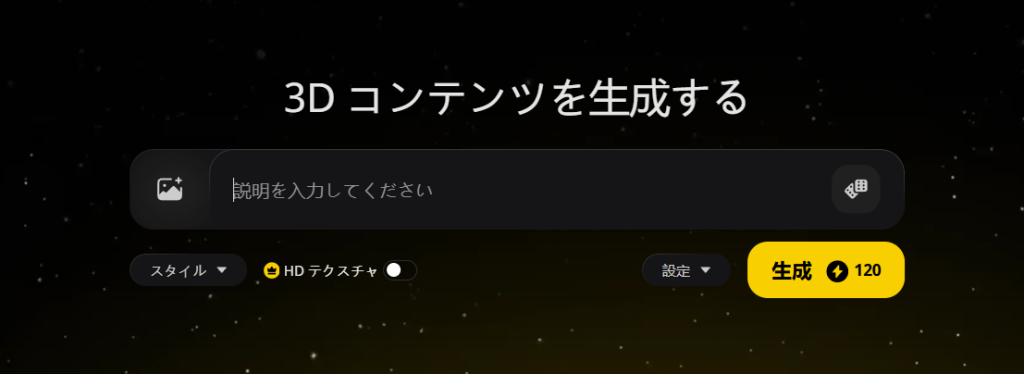
画像からの3Dモデル生成:アップロードした画像をもとに、AIが3Dモデルを作成します。
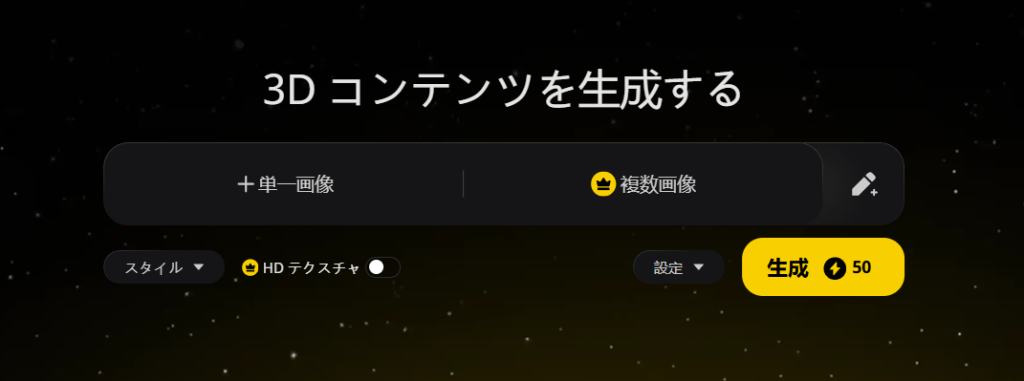
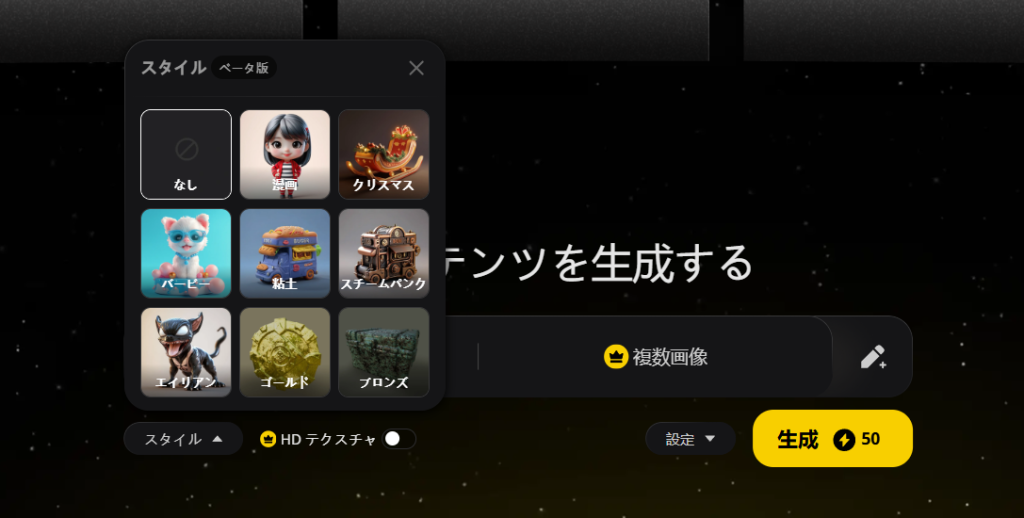
スタイル及びHDテクスチャ生成:生成モデルのスタイル、より精度が高いテクスチャを生成機能。
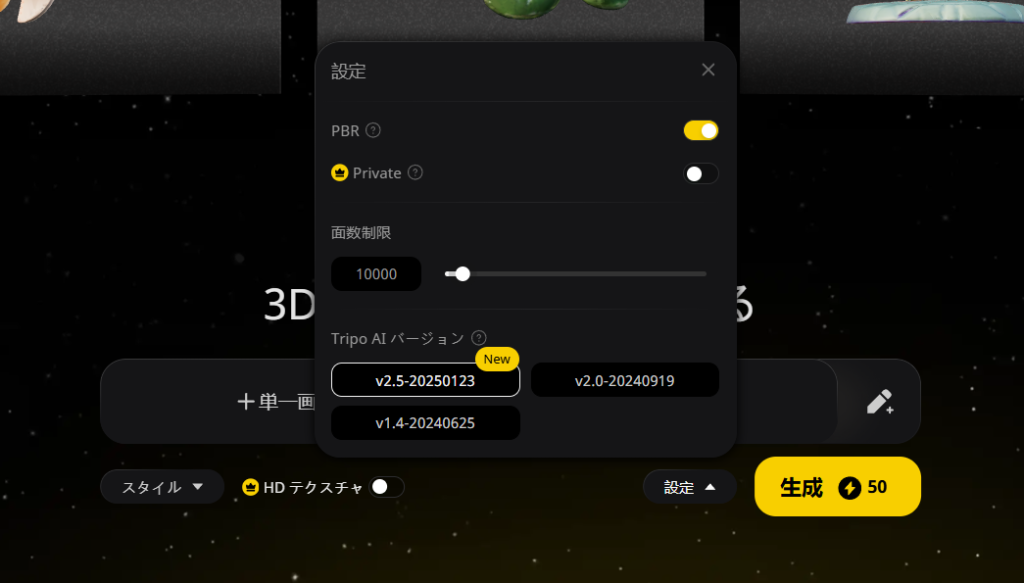
PBRテクスチャ、面数制限、AIバージョン:設定から自由に調整できます。
再トポロジーとエクスポート:生成したモデルのポリゴン数を最適化し、FBX、OBJ、GLBなど多様な形式でエクスポートできます。
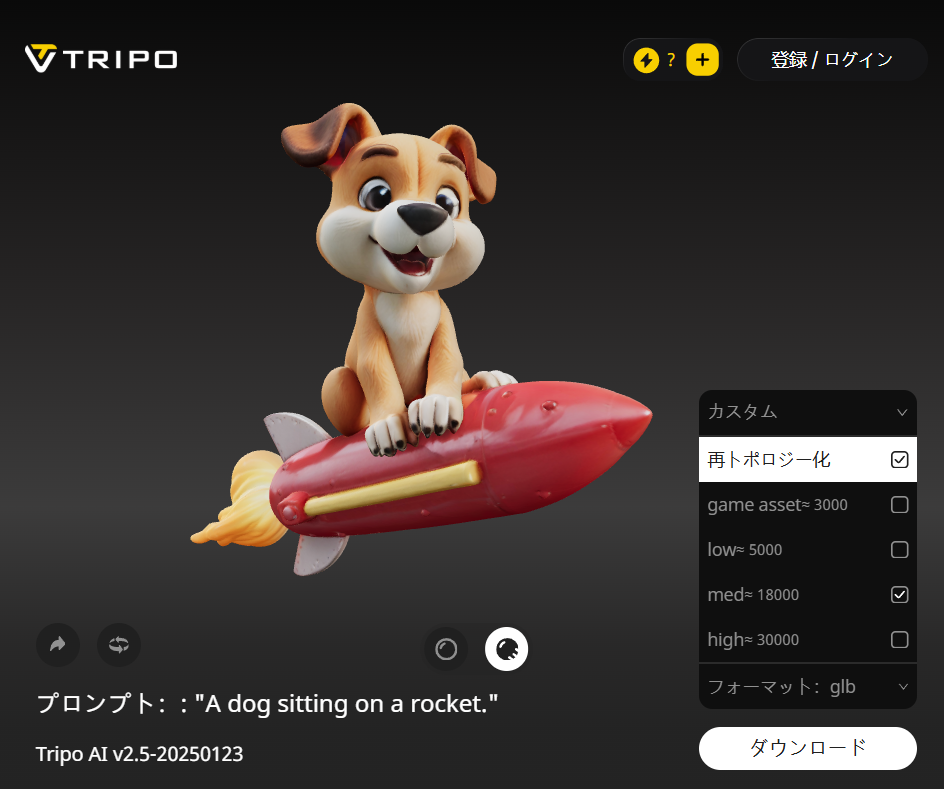
お試しなら無料プランで十分かなと思います。
無料プラン
- 月間クレジット:600ポイント(約24回分の3Dモデル生成)
- 1件のタスクが同時待機可能、
- 待ち行列の優先度は低め
- 生成モデルは公開設定のみ
- コミュニティサポートのみ
Meshy V5.0
主な機能
基本的に、Tripoと同じような機能を持っていますが、
テキストからの3Dモデル生成
画像からの3Dモデル生成
多様な形式エクスポート
一番違うのは、
一気に四つのプレビューモデルを生成し、結果に近いモデルを選択によって更に精度を高めた最終モデルを生成する所と、
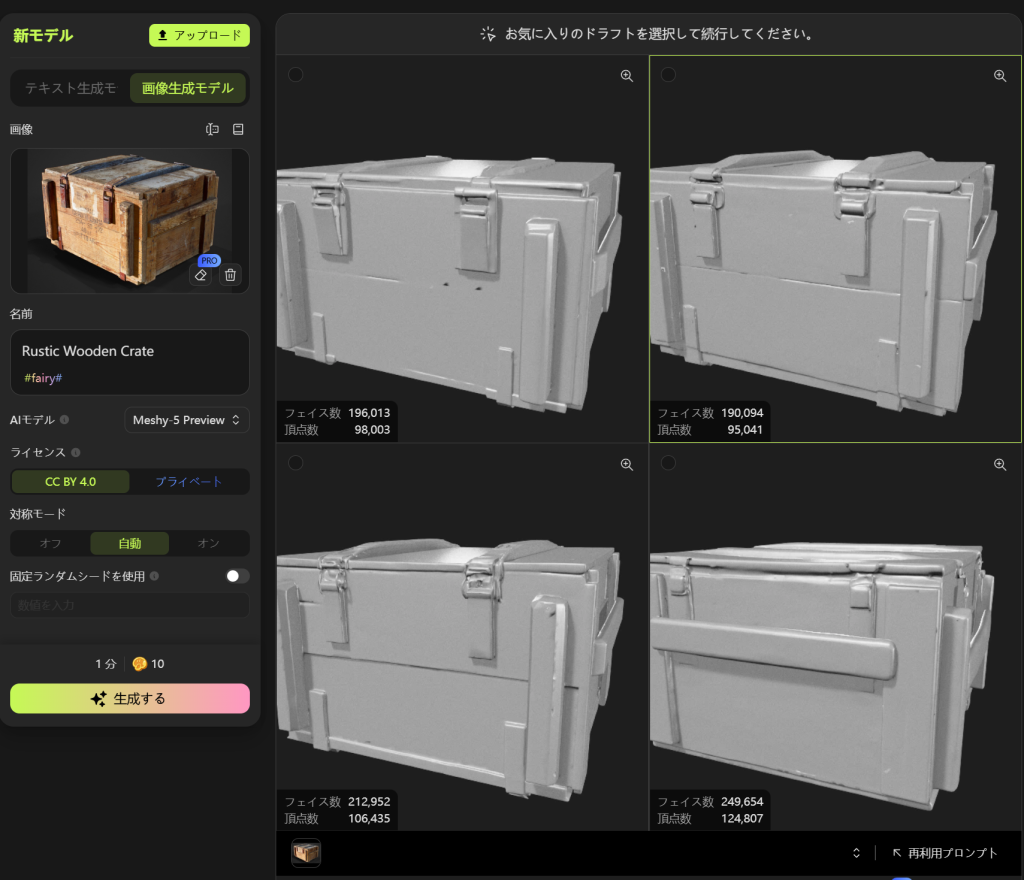
テクスチャに影なしのColorMapを生成可能の所です。


これは何がすごいかというと、
テクスチャに影を付くと、その影の向きが固定され、ライティングの角度を変えたら不自然になってしまいます。
一方で、テクスチャに影がなければ、シーンの照明に応じてライティングの角度を自由に調整でき、違和感のない自然な見た目になります。

お試しのフリープランなら
- 月間クレジット:100ポイント
- 月に3回のダウンロード
- アセットは CC BY 4.0 ライセンスに従います
- 最大 1 タスク、待ち行列の優先度は低め
Trellis
Trellis 3Dは、Microsoftが開発した最新のオープンソースAIモデルで、テキストや画像から高品質な3Dアセットを生成することに特化しています。
無料3Dモデル生成AIにおいて、最強です。
UIと操作もすごく簡単で、やりやすいと思います。
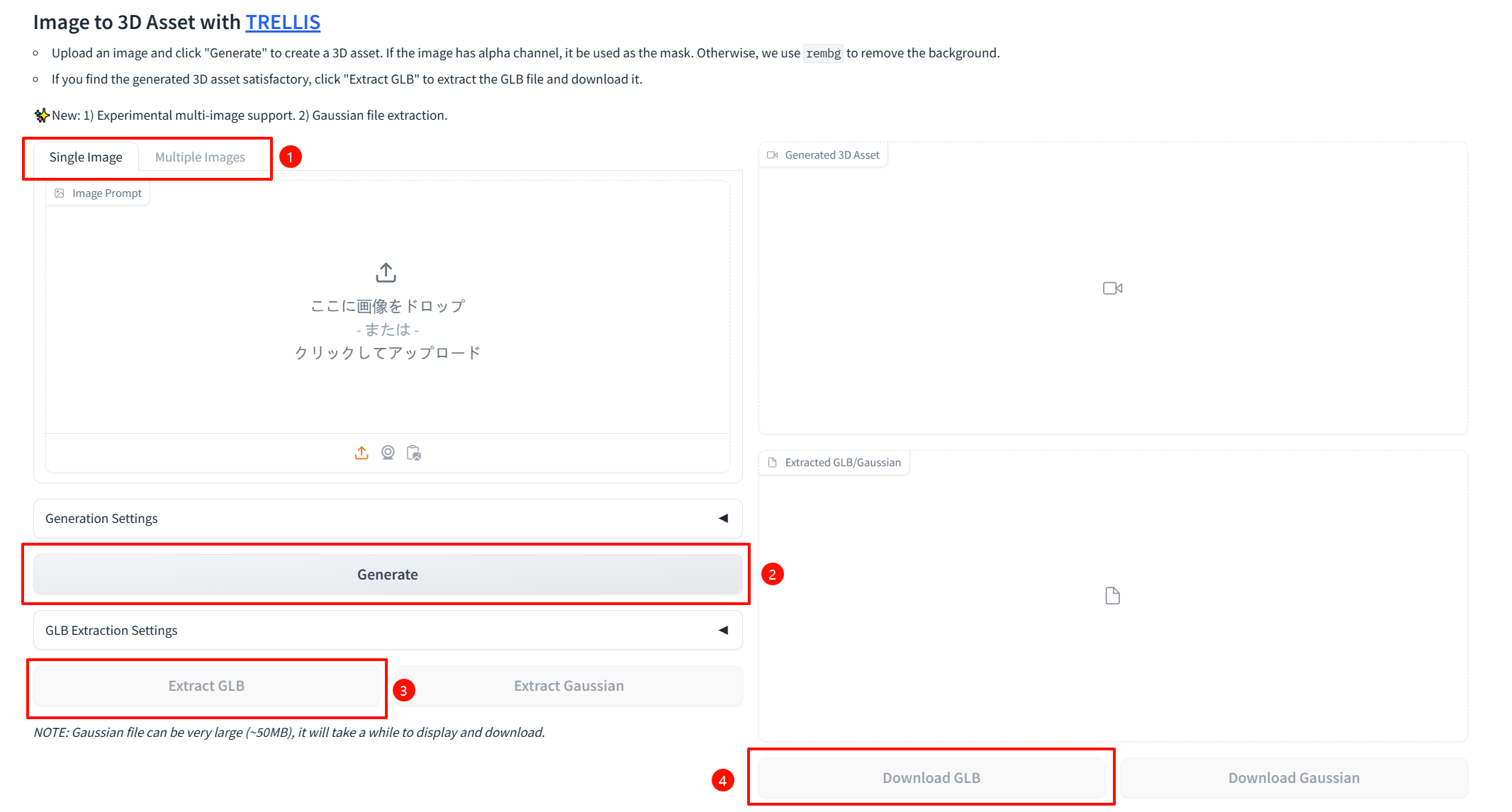
1、1枚画像 or 複数画像UP
2、Generate生成
3、Extract GLB
4、GLBダウンロード
例




メリット
- 無料、使いやすい。
- 速度、精度今まで一番高い。
- 画像背景自動的に切り抜かれます。
デメリット
- リトポロジー必要
- 複雑な物、生物モデルに精度足りない。(特に顔)
- テクスチャの精度がまだまだ低い。
ローカル環境への導入が可能です。
システム要件
- Pythonバージョン:Python 3.8以上が必要です。
- GPU:少なくとも16GBのVRAMを持つNVIDIA GPU(例:A100、A6000)が推奨されています。
- CUDAツールキット:GPUに対応する適切なCUDAバージョンが必要です。
Hunyuan3D-2
Hunyuan3D-2.0は、テンセント社が開発した最新のオープンソース3Dモデル生成AIシステムで、テキストや画像から3Dアセットを生成することができます。
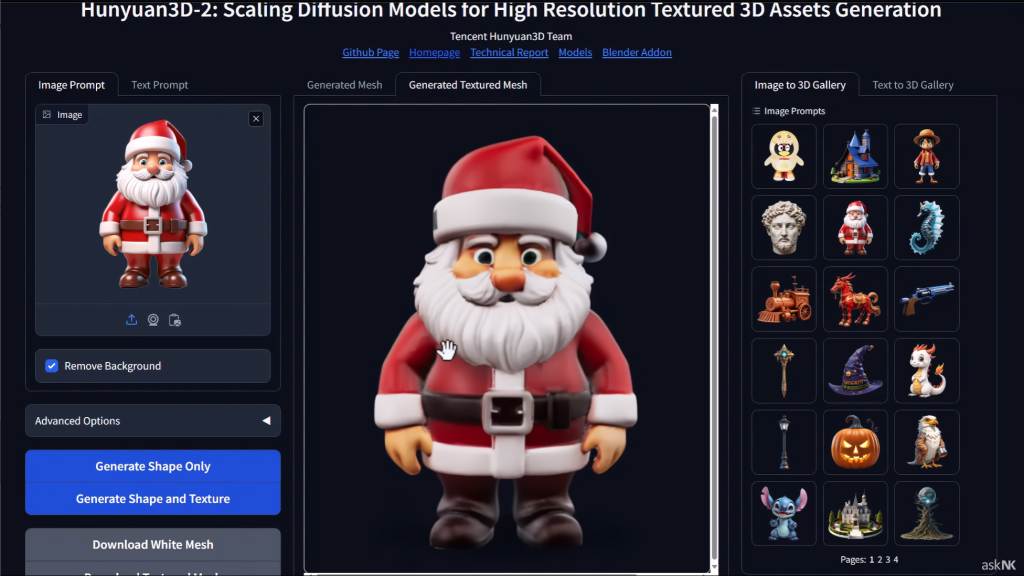
ほとんど複雑な操作はなく、Generateクリックするだけで、画像やテキストに基づいて3Dモデルを生成できます。

さらに、Blender対応するプラグインもあります、
Blenderでテキストや画像からモデル生成することができます。

オープンソースなので、もちろんローカル環境への導入が可能です。
システム要件
- Pythonバージョン:Python 3.10が必要です。
- GPU:少なくとも6GBのVRAMを持つNVIDIA GPU(例:RTX 4090)が推奨されています。
- CUDAツールキット:GPUに対応する適切なCUDAバージョンが必要です。
メリット
- 無料、使いやすい。
- 速度、精度が高い。
- 画像背景を切り抜き機能。
デメリット
- リトポロジー必要
- 複雑な物、生物モデルに精度足りない。(特に顔)
- テクスチャの精度がまだまだ低い。
普段の使い方やワークフロー
3DモデルAIには、テキストから3Dモデルを生成する機能がありますが、基本的には「テキスト→画像→3Dモデル」というプロセスで裏で行われます。
ただし、テキストから画像を生成する過程は表示されないため、私たちはその画像結果をコントロールしたり、選択・変更することができません。
そのため、まず画像生成AIを使って、納得のいくまで画像を作成し、その後に3Dモデルを生成することをおすすめです。
画像生成AIについて、個人のおすすめは、
ChatGPT 4o
最近のモデルアップデートにより、4oは画像の理解能力が大幅に向上し、高画質を維持しなが、物体のディテールの一貫性も保てるようになりました。
例:
元画像から、側面と背面図を生成してもらいます。


上半身画像から、全身三面図を生成してもらいます。


しかも、一発で完璧に生成してもらいました。
驚きですね。
Tripoでモデルを生成してみました、頭のデティールが凄く良いと思います。

Hunyuan3Dでも生成してみましたが、
Tripoと比べると、精度と品質はやや劣っていますね。
(まあ、無料ツールですので)

Google ai studio
画面の右側にAIモデルをGemini 2.0 Flash (Image Generation) 選択、
フォマードをImages and textに設定します。

そして、AIに線画を渡して、3DCG風の画像を生成するように指示します。

続いて、生成した画像の三面図を生成してくださいと指示します。

うまく出来てないですが、やや上角度からの画像をもらったので、
この2枚でTrellisに生成してみました、


正直、こんなもんですかね。
形状はほぼ近いですが、テクスチャ精度がまだ足りないかなと思います。
まとめ
現時点では、AIで作成される3Dモデルは、デフォルメされたものに対しては非常に優れた結果を期待できます。
しかし、やや複雑な構造を持つモデルとなると、精度や品質の面で商用レベルにはまだ達していないのが現状です。
ラフスケッチやコンセプトデザインの段階、あるいは簡易なプロトタイプの作成といった用途においては、非常に効率的なツールと思います。
今後さらに技術が進化すれば、より複雑で高精度な3Dモデルの生成も可能になることを期待が高まりますね。
いかがでしょうか、もし興味がございましたら、皆さんもぜひ使ってみてください!